Strukturen i en relasjonsdatabase (RDBMS) har som ett av flere prinsipper at data ikke skal dupliseres. Om en database inneholder personopplysninger, ligger disse i en egen tabell og man trenger dermed ikke å endre navn i alle oppføringer i databasen om et "medlem" i databasen skifter navn. Her ligger det vakre i RDBMS'er: Endre navnet i én rad, og alle datauttrekk benytter dette navnet i ettertid. Denne modellen kan være et eksempel:
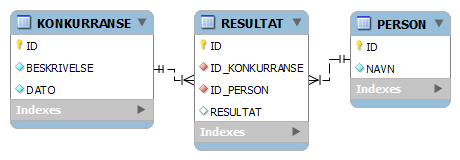
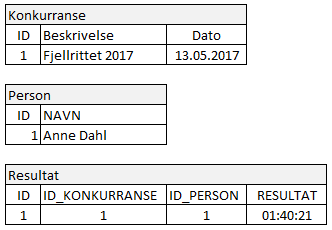
Det er modellen til et enkelt resultatregistreringssystem for en arrangør av sykkelrittet "Fjellrittet". Etter det første arrangementet har vi følgende data (arrangøren sliter foreløpig med deltakelsen):
Året etter så data slik ut:
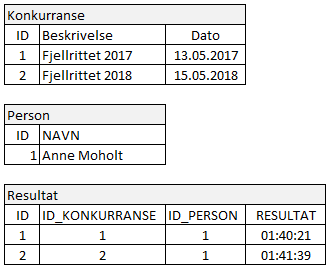
...den eneste deltakeren hadde skiftet navn etter skilsmisse.
Problemet dukker opp når idrettslaget publiserer denne databasen på nett, og man kan velge å få opp resultatlister for hver konkurranse. Etter navneendring ved påmelding til rittet i 2018 vil Anne Moholt stå som vinner av 2017-rittet, mens hun i 2017 deltok under navnet Anne Dahl. Dette mener idrettslaget er uakseptabelt, spørsmålet er hva vi kan gjøre med modellen for å løse dette ?
Felles for løsningsforslagene er at de kompliserer modellen, graden varierer. Ofte er det slik at den enkle løsninger rent modellmessig har andre slagsider som f.eks. mer komplisert SQL for å trekke data ut eller behov for triggere eller programfunksjonalitet for å sikre datakonsistens ved endrede data.
Den kanskje reneste løsningen:
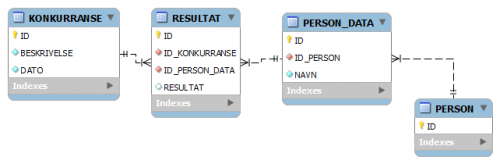
...ser litt underlig ut; "Hva er denne tabellen PERSON som bare inneholder en ID ?" Jo, den trengs for å kunne knytte sammen persondata for én og samme person, slik at det går an å liste opp Anne Dahl/Moholt sine resultater. Hadde man registrert en ny person ved endring av navn, ville koblingen vært tapt. Det gjenstår ett problem i denne løsningen: Hvordan vite hva som er gjeldende navn på deltakere som har flere navn opp gjennom tiden ? Det vil være den raden i PERSON_DATA med høyest ID, siden denne verdien øker for hver ny rad - alternativet kunne være å legge til en kolonne PERSON_DATA.GJELDENDE med verdi 0/1, og sørge for at kun siste rad for personen har denne satt til 1 ved f.eks. en trigger på PERSON_DATA.
Trenger man en slik modell for å kunne gjenskape historiske data ? Det kommer an på applikasjonen, og det finnes selvfølgelig andre måter å gjøre det på:
- La PERSON_DATA ha to datofelt som bestemmer gyldighetsperioden: DATO_FRA og DATO_TIL. I så fall kan man linke RESULTAT til PERSON i stedet for PERSON_DATA:
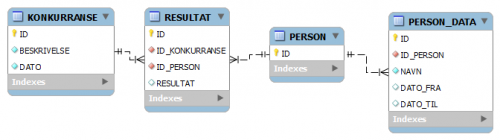
...men prisen å betale er at en join for å hente ut riktig PERSON_DATA må inneholde et datofilter i join fra RESULTAT til PERSON_DATA:
SELECT
R.RESULTAT,
PD.NAVN
FROM
RESULTAT R
JOIN
KONKURRANSE K ON K.ID = R.ID_KONKURRANSE
JOIN
PERSON_DATA PD
ON
PD.ID_PERSON = R.ID_PERSON
AND
PD.DATO_FRA <= K.DATO
AND
(PD.DATO_TIL >= K.DATO OR PD.DATO IS NULL)
En tredje variant er å ha en tabell PERSON med NAVN, og legge tidligere versjoner i en tabell PERSON_HISTORIKK:
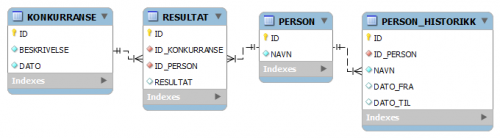
...nå slipper man problemet med å velge ut gjeldende PERSON_DATA for annet enn listinger for tidligere års konkurranser, fordi PERSON alltid holder gjeldende NAVN. Men - en enda mer komplisert spørring må nå gjøres mot PERSON og PERSON_HISTORIKK for tidligere konkurranser, den må sjekke om en historisk rad finnes og i tilfelle bruke dette navnet:
SELECT
R.RESULTAT,
COALESCE(PH.NAVN, P.NAVN) NAVN -- Fra historikk om NOT NULL
FROM
RESULTAT R
JOIN
KONKURRANSE K ON K.ID = R.ID_KONKURRANSE
JOIN
PERSON P
ON P.ID = R.ID_PERSON
LEFT JOIN
PERSON_HISTORIKK PH
ON
PH.ID_PERSON = R.ID_PERSON
AND
PH.DATO_FRA <= K.DATO
AND
PH.DATO_TIL >= K.DATO
...og dette er bare for å håndtere endringer i data for én tabell over tid....
Som sagt: Tidsakser i datamodeller er Ren Ondskap !